
How We Vibe-Coded a Large-Scale Prospect Enrichment Pipeline in a Weekend
The Business Problem
My employer generates leads for SMEs — painters, plumbers, roofers, installers. Their CRM holds hundreds of thousands of prospect records, each with a company name, an email address, and not much else.
The gap: no address data. No street, no city, no postcode, no phone number. For a lead generation business that routes jobs by geographic area, this is a real operational problem. Better location data means better campaign segmentation and cleaner cross-referencing against business registries.
The obvious fix — buy enriched data — costs thousands per batch and goes stale fast. The smarter fix: derive it ourselves from the data we already have.
Every prospect has an email. Every business email has a domain. Every domain (usually) has a website. And most SME websites list their address, phone number, and opening hours right on the homepage or contact page.
So we built a scraper.
The Goal
Given a CRM export, produce an enriched CSV with 21 new columns:
enriched_domain,enriched_websiteenriched_company_nameenriched_street,enriched_city,enriched_postcode,enriched_countryenriched_phone,enriched_phone_type,enriched_whatsappenriched_emailenriched_social_linkedin,enriched_social_facebookenriched_vat_number,enriched_kvk_numberenriched_business_typeenriched_opening_hours,enriched_website_languageenriched_employee_count,enriched_founding_yearenriched_confidence(high/medium/low/failed)enriched_source
All of this derived from the domain alone, in a resumable batch job that could run overnight on a cloud server.
How It Was Built (Vibe-Coded with Claude)
We didn't start with a spec and build to it. We started with a question — "how do we make this scraper succeed more?" — and iterated from there with Claude Code as the primary developer.
The Core Pipeline
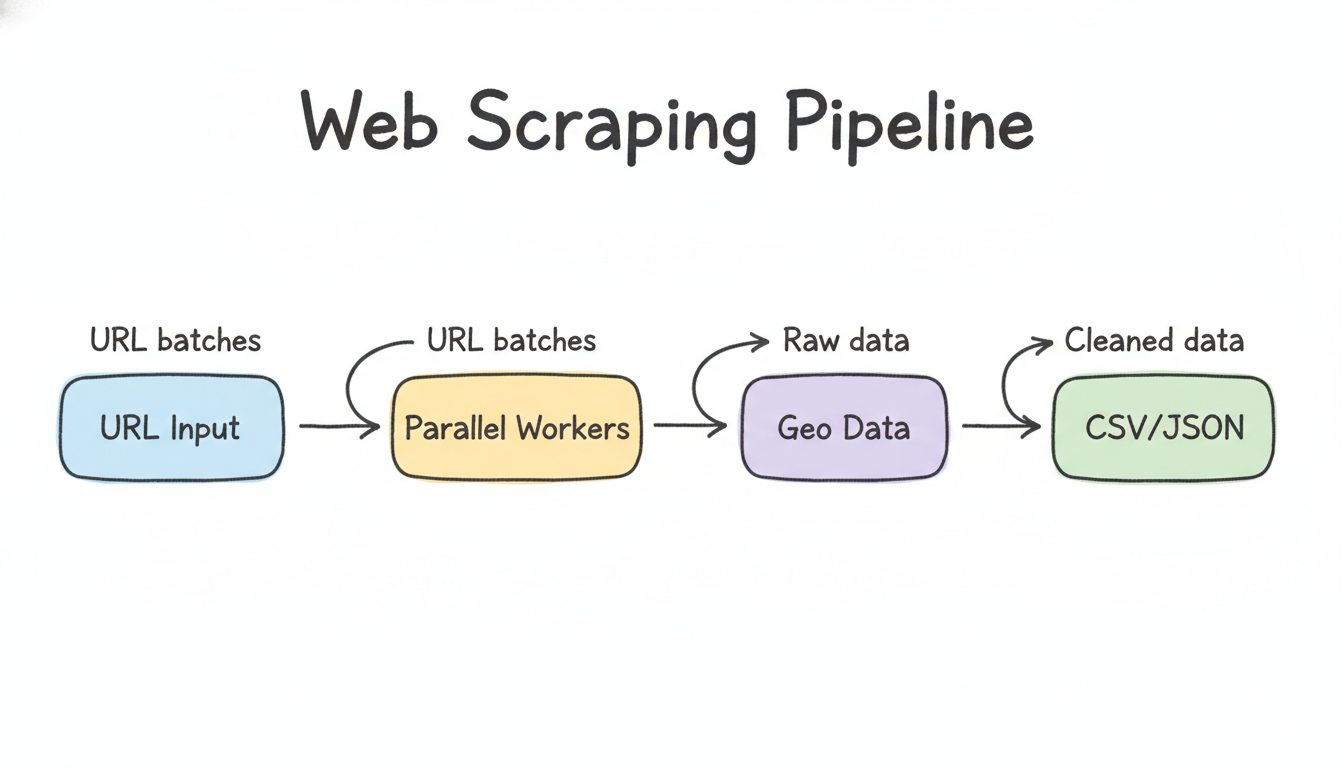
Four steps wired together in scripts/enrichment/enrich_prospects.js:
Domain extraction — parse each email's domain, skip 30+ free-mail providers (gmail, hotmail, and regional ISPs), deduplicate. Hundreds of thousands of records collapse to a much smaller set of unique business domains.
Scraper worker pool — fetch homepage + contact pages concurrently (configurable workers, default 5). Extract address data via schema.org JSON-LD first (structured markup that sites declare explicitly), then fall back to postcode regex patterns. Respects
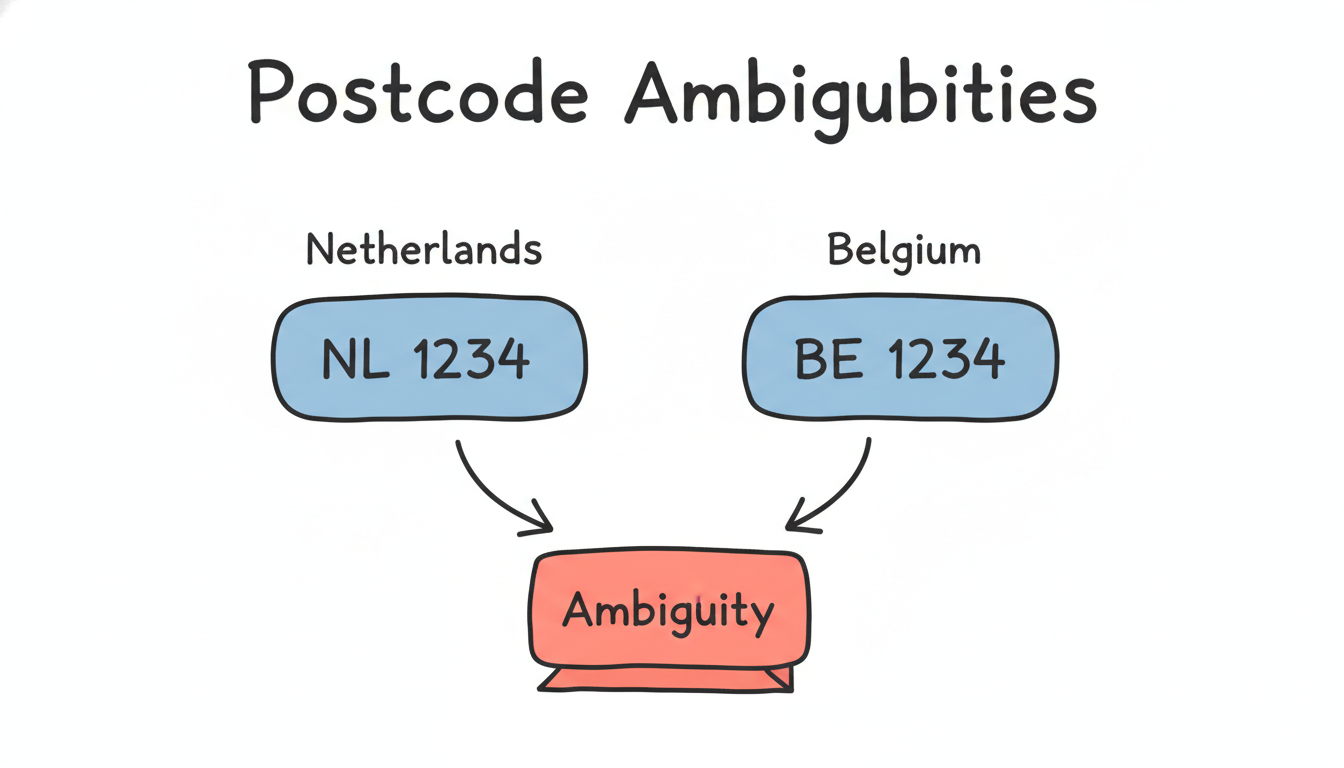
robots.txt, uses a politeBot/1.0User-Agent, enforces 200ms inter-request delay.Postcode resolver — validate every scraped postcode against in-memory reference tables (NL: 460k entries, BE: 2,500+ entries from Geopostcodes CSVs). Dutch postcodes are
1234 AB, Belgian are1234— the 4-digit-only Belgian format is genuinely ambiguous (is it a year? a phone fragment?), so we cross-validate against the reference table before accepting it.Writers — CSV writer appends the 21 enriched columns to the original rows. SQLite writer (
better-sqlite3) persists todata/results.dbfor multi-run aggregation and the GUI to query.
What We Iterated On
Exponential backoff — websites return 429/503 when we hit them too fast. We added fetchWithBackoff: 1s → 2s → 4s → 8s → 32s delays on rate-limited responses, up to 4 retries. Drop rate from bot-blocking fell noticeably.
Fuzzy postcode matching — typos in website data like 4811AB when the real postcode is 4811AA. We generate all 1-character substitution variants of the scraped postcode and check each against the reference map. If a variant exists, we return the canonical version, not the typo.
Employee count + founding year — schema.org numberOfEmployees and foundingDate fields are present on a surprising number of SME sites (often auto-generated by their CMS). We extract these and surface them as enriched columns.
Cross-source validation — we also import structured data from national business registries. When both the scraper and a registry agree on the city name for a domain, confidence upgrades from medium to high.
Multi-source adapters — beyond scraping, we built importers for Dutch and Belgian business registries, the French SIRENE API, UK Companies House, and Google Places.
DNS pre-filter — bulk DNS resolution before the main run pre-marks dead domains in the checkpoint, saving hours of scraper time on domains that don't resolve.
The Electron GUI
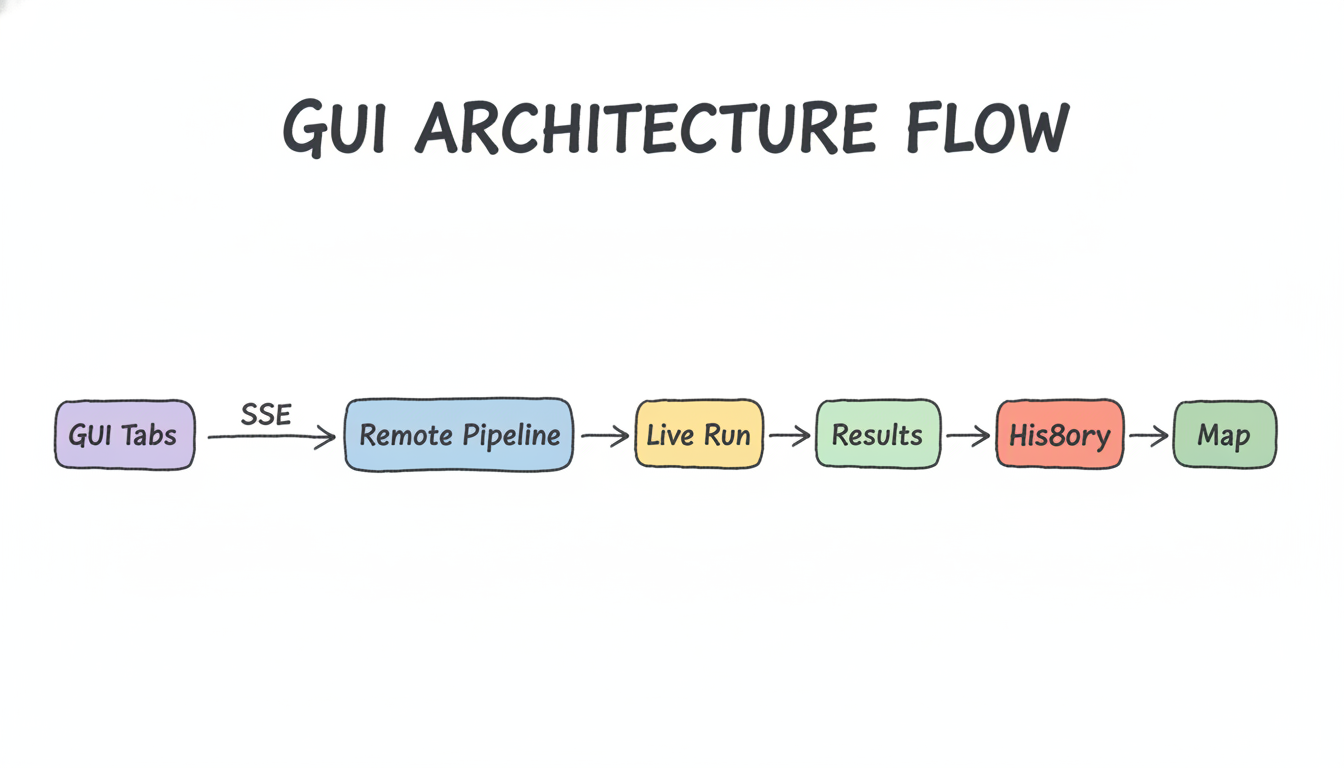
The scraper runs headless on a remote server, but we wanted to watch it in real time from the laptop. We built a small Electron app that connects via SSE (Server-Sent Events) to the remote pipeline and shows:
- Live Run tab — progress bar, speed (rolling 2-min average), ETA, confidence breakdown, live domain feed
- Results tab — queryable view of the enrichment database, filterable by confidence
- History tab — per-run summary table (records processed, confidence breakdown, runtime)
- Map tab — Leaflet.js + OpenStreetMap, clustered CircleMarkers colored by confidence (green=high, amber=medium, grey=low, red=failed), filterable by country and business type. Powered by Nominatim geocoding.
The GUI connects to whichever server you point it at — localhost for dev, a remote server for production runs.
What We Learned
Scraping success rates vary widely. A meaningful share of records will hit bot-blocking (Cloudflare, CAPTCHA walls), JS-heavy single-page apps with no crawlable content, or sites with no contact page at all. Plan for it — checkpoint your progress, make the pipeline resumable, and measure confidence rather than treating all output as equal quality.
Schema.org is underrated. A meaningful percentage of SME websites — especially those built on WordPress with an SEO plugin, or Wix/Squarespace — declare their address in JSON-LD <script> blocks in the <head>. This gives us clean, structured data without regex gymnastics.
Belgian postcodes are a trap. A 4-digit number on a .nl domain site could be a year, a product code, a phone fragment, or an actual Belgian postcode. Always cross-validate against the reference table.
better-sqlite3 is excellent for this workload. Synchronous API, WAL mode, fast upserts. No async complexity, no connection pooling. For a single-writer pipeline it's perfect.
Windows packaging with native modules is annoying. better-sqlite3 is a native Node.js addon compiled against a specific Node ABI. Electron ships its own Node.js with a different ABI than system Node. Every time you package the app on Windows you need to run @electron/rebuild against the root node_modules first, or the packaged app throws ABI mismatch errors at runtime. We added this to the build script.
Vibe-coding works for pipeline tools. The pipeline went from "basic scraper" to "multi-source, confidence-scored, resumable, GUI-monitored, geocoded" through a series of natural conversations — describe the problem, get a working implementation, observe what breaks, iterate. No upfront architecture document, no story pointing. The tradeoff: you need to understand the code well enough to sanity-check what's produced, or you'll ship subtle bugs (e.g. the Belgian postcode false-positive problem wasn't in the initial version).
Stack
| Layer | Technology |
|---|---|
| Runtime | Node.js 20, ES modules |
| Scraping | node-fetch, cheerio, custom schema.org extractor |
| Phone | libphonenumber-js (E.164 normalisation + mobile/landline/voip classification) |
| Storage | better-sqlite3 (WAL mode) |
| Geocoding | OpenStreetMap Nominatim (strict 1 req/sec) |
| GUI | Electron 29, Leaflet.js, MarkerCluster |
| Tile layer | OpenStreetMap |
| Packaging | electron-builder + @electron/rebuild |
| Hosting | Cloud server |
| AI pair | Claude Code (Sonnet 4.6) |
Built in-house, March 2026.